Harder Than You Think
2025-12-01
It's October 2017 and Vitalik is speaking at an Ethereum meetup at Stanford. The topic is a technical one called the data availability problem.
In that talk he introduces the now famous Scalability Trilemma. If you have been around the blockchain space long enough, you have probably heard it hundreds of times.
In two days, Ethereum will ship a big step toward solving that trilemma in production. The Fusaka upgrade will activate PeerDAS, a new way for nodes to check that block data is available without every node downloading everything. This post is my attempt to explain why that matters, starting from that 2017 meetup and ending with where we are today.
The trilemma is the idea that a blockchain can only achieve two of the following three properties at the same time.
- Decentralized: People can run a node on a regular laptop
- Scalable: The network can handle way more activity than a single laptop can process
- Secure: The network stays safe even if a large attacker tries to cheat

Ethereum developers decided that decentralization and security were non-negotiable. The plan was to scale while still letting regular people run nodes at home, even if the exact path was not obvious yet.
To see why this is hard, compare Ethereum to a traditional system. JP Morgan runs tens of thousands of servers across multiple data centers. They split the load across many machines. Ethereum does not. Every node replays every transaction, so the entire network is bottlenecked by the compute and bandwidth of a single laptop.
This design is what keeps Ethereum decentralized. Anyone can run a node at home. When thousands of people run nodes around the world, the network becomes extremely hard to shut down. There is no single data center to target, no company to pressure, and no switch to flip.
This idea comes directly from the cypherpunks, who built systems designed to survive government pressure. Early digital money systems like e-gold and Liberty Reserve failed because they relied on single operators who could be arrested or shut down. If you want something to last, it has to be peer to peer and widely distributed.
The same is true for blockchains. If users are not running nodes, a few large operators can quietly change the rules, mint new coins for themselves, or rewrite balances. Vitalik explains it better than I can:

But the short version is simple: users are the final line of defense.
This also explains why some shortcut approaches to scaling do not work. Several networks raised hardware requirements until only data center machines could run full nodes. On paper this looks like scaling, but in practice it recreates the same choke points blockchains were invented to avoid. If those servers get pressured or shut down, the network goes down with them. We have seen this happen in real life. Hetzner shut off access to Solana validators and took a large part of the network offline.
And once hardware requirements rise, regular users stop running nodes at home. Only a small group ends up enforcing the rules. If those operators ever coordinate, users cannot push back. In the worst case they can push through blocks that change balances or mint new coins for themselves, and then it is gg’s thanks for playing.
The shortcut does not solve scaling anyway. It only moves the bottleneck from one laptop to one data center machine. But if blockchains are going to support global activity, they eventually need the equivalent of thousands of machines working together. One machine, no matter how powerful, always hits a ceiling.
This is why Ethereum refused the shortcut. But all of this sets up the real challenge. Solving the trilemma while being bottlenecked by the compute and bandwidth of a regular computer turned out to be one of the hardest research and engineering problems in all of crypto.
When Ethereum went live in 2015 the network could process only a small number of transactions. Scaling Ethereum while keeping node requirements low meant solving two completely different problems.
The first is scaling execution. Execution is the actual compute needed to check that all the transactions in a block were processed correctly. In 2015 the only known way to do this was the obvious way: go through every transaction one by one and verify each step. That works, but it means the total computation per block is capped by what a single laptop core can handle.
The second is scaling data availability. Data availability is the storage and bandwidth needed to make sure the network actually has all the transaction data in a block. It is not enough to know a block’s transactions were processed correctly. You also need access to the actual transactions themselves. That means the network has to hold this data and have the bandwidth to send it around to everyone who needs it. In 2015 the only known way to do this was the obvious one: every full node downloaded the entire block and all of its data and then shared it with the rest of the network. That works, but it means the amount of data per block is capped by what a single laptop can reliably download and upload.
Another way to think about data availability is with a simple example Bartek from L2Beat once gave on The Edge Podcast. Imagine your bank tells you your balance is $12,000 but you are sure it should be $65,000. The first thing you would do is ask for the list of transactions so you can recompute the balance yourself. That is normal. You expect the bank to give you the data so you can verify the result.
Now imagine the bank says “trust us, we will not show you the transactions.” No one would accept that. Without the underlying data, you cannot verify anything.
Blockchains work the same way. It is not enough for the network to say a block is valid. Users need access to the actual transaction data so they can verify the state for themselves. If even a small part of the data is missing or withheld, it becomes impossible to check your own balance or rebuild the chain. That is the core idea behind data availability.
Ethereum researchers knew from the very beginning that solving both execution and data availability would require some form of sharding. You can even see it in early posts from 2014. The idea was already clear years before the network went live.
Sharding in this context means splitting the workload across many parts of the network so that not every node has to do everything. One group of nodes can process one set of transactions, another group can process a different set, and the protocol can combine the results into one chain. This is the only way to scale without forcing every node to handle the entire global workload.
The direction was understood, but the exact design was still completely open. It was real research, not engineering.
Now fast forward to the Stanford Ethereum meetup in 2017 where this story began. Three years had passed since those early research threads in 2014. By 2017 the research on scaling data availability had started to make real progress. At this meetup Vitalik presented a credible path forward.
 In 2018 he, along with Mustafa Al-Bassam and Alberto Sonnino, wrote it up as a formal: https://arxiv.org/abs/1809.09044.
In 2018 he, along with Mustafa Al-Bassam and Alberto Sonnino, wrote it up as a formal: https://arxiv.org/abs/1809.09044.
The solution involves a mix of cryptography and probability and is called data availability sampling.
Vitalik once used an analogy that I think captures the idea well. Imagine you are an orange farmer with 5,000 oranges and you want to know if the entire batch is ripe. You do not need to check every single orange. You can pick a random sample, like 25 of them. If all 25 look good, you start to build confidence that the whole batch is probably fine.
But probably fine is not good enough, we need to know the whole batch is ripe. If you serve someone a not ripe orange you could get sued and lose your business!
Now, imagine you use a special pesticide, in reality this is cryptographic polynomial jedi magic, where if at least 50 percent of the oranges are ripe, the pesticide guarantees the whole batch will behave as if it is ripe.
So you pick 25 random oranges. If all 25 are ripe, you can start building confidence that at least half of the entire batch is ripe. The more random oranges you check, and the more of them that are ripe, the stronger your confidence becomes. Very quickly you reach near certainty (99.99 percent) that the batch meets the threshold, without having to check every single orange.
In Ethereum, DAS works the same way. A block might contain thousands of transactions, but instead of every node downloading all of them, each node only downloads a few random slices of the block, maybe something like one eighth of the data. If all the slices it checks look valid, the node becomes confident the entire block’s data is available. If any part of the data is missing or being withheld, nodes will almost always catch it in their random samples and reject the block. This lets Ethereum safely handle much larger blocks without forcing every node to download everything.
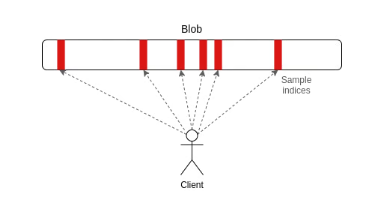 DAS: Check a small amount of data and yet know it's all available to download
DAS: Check a small amount of data and yet know it's all available to download
That is my oversimplified version of the idea. If you want the real thing, search “Ethereum data availability sampling” or ask ChatGPT for a proper explanation. The point of this post is not to give a deep technical breakdown of the upgrade. It is to show how the pieces fit together and why this moment matters.
And this is where the all the pieces of the post start fitting together. Once the direction was understood, there were still huge unsolved problems. How would the mempool scale? How would all the new transactions be spread across the network? How would nodes coordinate if they need to reconstruct the data?
But after almost a decade of refusing to take shortcuts, the work has paid off. In two days, data availability sampling will be live on Ethereum through PeerDAS. Ten years after the network launched, Ethereum is about to solve half of the core scaling problem in production. Fusaka is a monumental moment for Ethereum.
The data availability problem is not completely solved yet. PeerDAS is the first step, and it is the first time Ethereum is doing this in production. The network will start with a conservative number of blobs and slowly increase the amount of data over time as clients, researchers, and operators build confidence. But the important part is that the foundation is now in place. For the first time, Ethereum can safely raise data capacity without raising hardware requirements. This is how blockspace grows by 10x, then 100x.
One of the beautiful things about the rollup centric roadmap is that it lets Ethereum scale without shipping data availability scaling and execution scaling in production at the same time. Doing both at once would have been extremely complex and risky. Rollups gave us room to solve these two problems separately, in the right order, and without rushing upgrades that touch the core of the protocol.
And as exciting as PeerDAS and Fusaka are, execution scaling is also making real progress. That is a topic for another post. For now I will just say this, keep an eye on ethproofs.org.
PeerDAS is the first moment where the trilemma starts to bend in practice. The rule has always been that you cannot stay decentralized on laptop-sized hardware and still handle way more activity than a single laptop can process. Sharding is the only path around that boundary, and with Fusaka, Ethereum is about to run that path in production for the first time. It is one step closer to a future where thousands of laptops around the world power the internet of value.
So, Happy Fusaka! Happy PeerDAS! Don’t forget to thank your local core dev and researcher, and cheers to choosing hard work over shortcuts despite all the external pressure.
Special thanks to Emily Rasowsky for feedback and review.